





AltME groups: search
Help · search scripts · search articles · search mailing listresults summary
| world | hits |
| r4wp | 142 |
| r3wp | 454 |
| total: | 596 |
results window for this page: [start: 1 end: 100]
world-name: r4wp
| Group: #Red ... Red language group [web-public] | ||
| Jerry: 5-Aug-2012 | Doc, Not to rush you, just curious about the progress of Red and its Unicode support. Unicode is very important here in China. :-) | |
| DocKimbel: 5-Aug-2012 | Red: I'm still working on both the compiler and the minimal runtime required to run simple Red programs. I have only the very basic datatypes working for now, no objects (so no ports) yet. I not yet at the point where I can give an accurate ETA for the first alpha, but I hope to be able to provide that ETA in a week. Red string! datatype will support Unicode (UTF-8 and UTF-16 encoding internally). I haven't implemented Unicode yet, so if some of you are willing to provide efficient code for supporting Unicode, that would greatly speedup Red progress. The following functions would be needed (coded in Red/System): - UTF-8 <=> UTF-16 LE conversion routines - (by order of importance) length?, compare (two strings), compare-case, pick, poke, at, find, find-case - optinally: uppercase, lowercase, sort All the above functions should be coded both for UTF-8 and UTF-16 LE. | |
| DocKimbel: 23-Aug-2012 | You mean the C source code I posted, I guess it's a Unicode main() from VisualStudio, you can safely replace it with a standard main(). | |
| DocKimbel: 4-Sep-2012 | I should be able to make a "hello word" script in Red in a few days. I still have to make some design decision wrt Unicode internal handling, that's really a complex part. | |
| Pekr: 4-Sep-2012 | Doc - what I noticed (and please don't take it personally) is, that sometimes you miss on how R3 was designed and solved some areas. Maybe you could talk to BrianH, who knows lots of things about what was/is good about R3, so that you can take similar path? E.g. Unicode support took Carl 2-3 months ... | |
| DocKimbel: 4-Sep-2012 | Pekr: thanks for the advice. :-) I haven't followed very closely the developpement of R3 nor I have ever wrote R3 code, so I'm not aware of all the reasons for some design decisions. That's why I ask when I need to. AFAIU, R3 was designed to solve R2 issues. I'm building Red from scratch, so I don't have legacy issues (so far) to deal with, I have more freedom than Carl with R3 and I intend to use it. They are some parts of R2/R3 design that fit well my plan, so I use them as inspiration, but there are other parts (especially in R3), that I am not fan of. Also, do I need to remind you that Red is compiled while R3 is interpreted? These are two different models which require different trade-offs. The difficulties I have to deal with in Red (both design and construction process) are inherent part of any non-trivial work to build something new and that's my role to solve and overcome them. The best way others can help me are by pointing out errors or inconsistencies both in the design and implementation. Wrt Unicode support, I should be able to say in a few days how long it will take to support it. I doubt I need as much as 2-3 months, but anyway, nobody but Carl knows what he had put in, and exactly how long it took him. ;-) | |
| Jerry: 4-Sep-2012 | I am glad that you are doing the Unicode part now. Better support it sooner than later. Back to 2008, I was one of the three Unicode testers for Carl, and I found many bugs and reported them back to Carl before he released it to the public. | |
| BrianH: 4-Sep-2012 | There is a bit that is worth learning from R3's Unicode transition that would help Red. First, make sure that strings are logically series of codepoints. Don't expose the internal structure of strings to code that uses them. Different underlying platforms do their Unicode APIs using different formats, so on different platforms you might need to implement strings differently. You don't want these differences affecting the Red code that uses these strings. Don't have direct equivalence between binary! and string! - require conversion between them. No AS-STRING and AS-BINARY functions. Don't export the underlying binary data. If you do, the code that uses strings would come to depend on a particular underlying format, and would then break on platforms where the underlying format is different. Also, if you provide access to the underlying binary data to Red code, you have to assume that the format of that data can be corrupted at any moment, so you'll have to add a lot of verification code, and your compiler won't be able to get rid of it. Work in codepoints, not characters. Unicode characters are complicated and can involve multiple codepoints, or not, but until you display it none of that matters. R3 uses fixed-length encodings of strings internally in order to speed things up, but that can cause problems when running on underlying platforms that use variable-length encodings in their APIs, like Linux (UTF-8) and Windows/Java/.NET/OSX? (UTF-16). This makes sense for R3 because the underlying code is compiled, but the outer code is not, and there's no way to break that barrier. With Red the string API could be logical, with the optimizer making the distinction go away, so you might be able to get away with using variable-length encodings internally if that makes sense to you. Length and index would be slower, but there'd be less overhead when calling external API functions, so make the tradeoff that works best for you. | |
| sqlab: 4-Sep-2012 | I am for sure no expert regarding unicode, but as red is a compiler and open source, why not not add flags that the user has to choose which unicode/string support he wants; either flexibility, but of cost of speed or no unicode support, then he has to do the hard work by himself | |
| BrianH: 4-Sep-2012 | One hypothetical advantage you have with Red is that you can make the logical behavior fairly high-level and have the compiler/optimizer get rid of that at runtime. REBOL, being interpreted, is effectively a lower-level language requiring hand optimization, the kind of hand optimization that you'd want to prohibit in Red because it would interfere with the machine optimization. This means that, for strings at least, it would make sense to have the logical model have a lot of the same constraints as that of R3 (because those constraints were inherent in the design of Unicode), but make the compiler aware of the model so it can translate things to a much lower level. If you break the logical model though, you remove the power the compiler has to optimize things. | |
| BrianH: 4-Sep-2012 | sqlab, it would make sense to have the user choose the underlying model if you are doing Red on bare metal and implementing everything yourself, or running on a system with no Unicode support at all. If you are running a Red program on an existing system with Unicode support, the choice of which model is best has already been made for you. In those cases choosing the best underlying model would best be made by the Red porter, not the end developer. | |
| sqlab: 4-Sep-2012 | but that means, that Red has to support all unicode models on all the systems, it can be compiled for. | |
| BrianH: 4-Sep-2012 | That's not as hard as it sounds. There are only 3 API models in wide use: UTF-16, UTF-8, and no Unicode support at all. A given port of Red would only have to support one of those on a given platform. | |
| DocKimbel: 4-Sep-2012 |
So far, my short-list of encodings to support are UTF-8 and UTF-16LE.
UTF-32 might be needed at some point in the future, but for now,
I'm not aware of any system that uses it?
The Unicode standard by itself is not the problem (having just one
encoding would have helped, though). The issue lies in different
OSes supporting different encodings, so it makes the choice for an
internal x-platform encoding hard. It's a matter of Red internal
trade-offs, so I need to study the possible internal resources usage
for each one and decide which one is the more appropriate. So far,
I was inclined to support both UTF-8 and UTF-16LE fully, but I'm
not sure yet that's the best choice. To avoid surprizing users with
inconsistent string operation performances, I thought to give users
explicit control over string format, if they need such control (by
default, Red would handle all automatically internally). For example,
on Windows::
s: "hello" ;-- UTF-8 literal string
print s ;-- string converted to UCS2 for printing through win32
API
write %file s ;-- string converted back to UTF-8
set-modes s 'encoding 'UTF-16 ;-- user deciding on format
or
s/encoding: 'UTF-16
print length? s ;-- Length? then runs in O(1), no surprize.
Supporting ANSI as internal encoding seems useless, being able to
just export/import it should suffice.
BTW, Brian, IIRC, OS X relies on UTF-8 internally not UTF-16.
| |
| BrianH: 4-Sep-2012 | Thanks, I don't know much about OSX's Unicode support. | |
| BrianH: 4-Sep-2012 | Be sure to not forget the difference between UTF-16 (variable-length encoding of all of Unicode) and UCS2 (fixed-length encoding of a subset of Unicode). Windows, Java and .NET support UTF-16 (barring the occasional buggy code that assumes fixed-length encoding). R3's current underlying implementation is UCS2, with its character set limitations, but its logical model is codepoint-series. | |
| BrianH: 4-Sep-2012 | IIRC Python 3 uses UCS4 internally for its Unicode strings, with all of the overhead that implies. UCS4 and UTF-32 are the same thing, both fixed-length. | |
| DocKimbel: 12-Sep-2012 | I will write about Red Unicode support in a blog article this week. | |
| Pekr: 22-Sep-2012 | Ah, Unicode plan posted, should be announed here :-) http://www.red-lang.org/2012/09/plan-for-unicode-support.html | |
| DocKimbel: 24-Sep-2012 | Red is now Unicode from end to end: http://t.co/FR8vNV65 | |
| DocKimbel: 24-Sep-2012 | Brian: you don't read Red's blog? :-) See http://www.red-lang.org/2012/09/plan-for-unicode-support.html | |
| Oldes: 25-Sep-2012 | (sorry that my question is out of topic... I was offline when I send it without noticing the unicode news:) | |
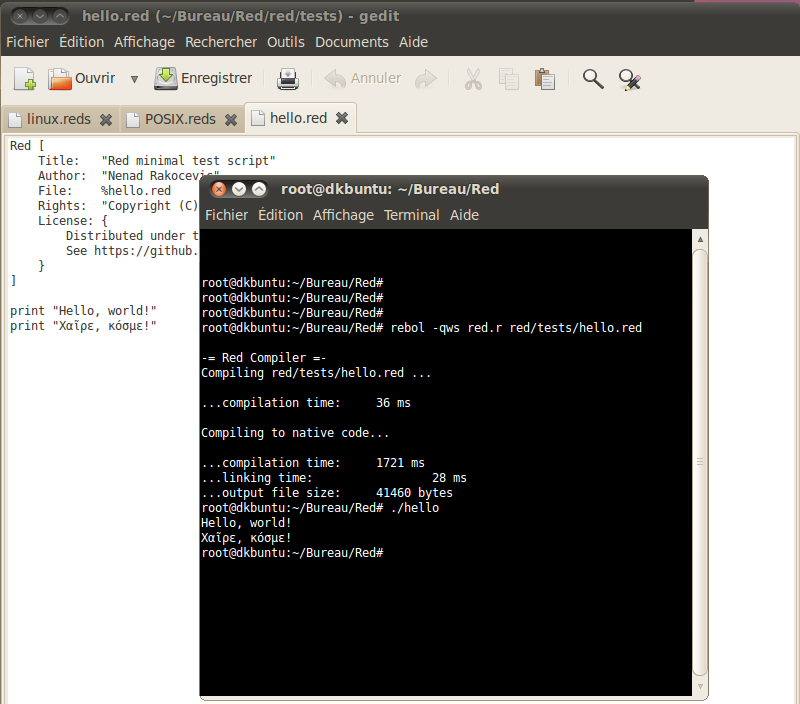
| DocKimbel: 25-Sep-2012 | Red Unicode printing support extended to all Unix platforms: http://static.red-lang.org/hello_unicode2.png | |
| DocKimbel: 25-Sep-2012 | For those testing Unicode output on Windows, you need to change the default raster font of DOS console to Consolas (recommended) or Lucida. The default font is unable to print Unicode characters. | |
| DocKimbel: 26-Sep-2012 | You can use any Unicode character in your Red words. | |
| Henrik: 26-Sep-2012 | You can use any Unicode character in your Red words. - ok, that was what I was looking for, as R3 can do this. Thanks. | |
| Jerry: 26-Sep-2012 | Graham is right, In Chinese, "World Hello" is better than "Hello World". You can change it if you want, Doc. :-) But I saw other langauge, such as Falcon, use "Hello World" in Chinese to demo their unicode support. | |
| DocKimbel: 26-Sep-2012 | Pekr: switch to Consolas which has the best range of Unicode glyphs support. | |
| DocKimbel: 26-Sep-2012 | Pekr: try typing your Czech characters in Notepad (it has excellent Unicode support). | |
| DocKimbel: 26-Sep-2012 | Anyway, we need more people testing Unicode support for Windows console, just in case we missed something. | |
| DocKimbel: 26-Sep-2012 | Here, I have no issue using Notepad to write Red Unicode scripts. | |
| DocKimbel: 26-Sep-2012 | You can still download Notepad++ (or any other text editor with decent Unicode support). I have to drop my good old TextPad as it doesn't have good Unicode support. | |
| Pekr: 26-Sep-2012 | above mentioned C4 9B is cuasing following output at the end of the phrase - strange .... http://www.xidys.com/pekr/red/red-unicode-bug.jpg | |
| DocKimbel: 26-Sep-2012 | You can find the codepoints you need here: http://en.wikipedia.org/wiki/List_of_Unicode_characters | |
| DocKimbel: 26-Sep-2012 | I have opened a piratepad page for copy/pasting Unicode strings: http://piratepad.net/782CD4w2Ni | |
| MagnussonC: 26-Sep-2012 | Tested "Hall� V�rlden!" on Win 7 (UTF-8) and it works. Saving the file as Notepads "Unicode" doesn't work, but I understand "Unicode" isn't supposed to be UTF. | |
| DocKimbel: 26-Sep-2012 | I guess that "Unicode" mode of Notepad is UTF-16. Red accepts only UTF-8 input scripts. | |
| Pekr: 26-Sep-2012 | the square char can be seen on the screenshot I posted - http://www.xidys.com/pekr/red/red-unicode-bug.jpg | |
| Pekr: 26-Sep-2012 | http://xidys.com/pekr/red/red-unicode-bugs.jpg | |
| Andreas: 26-Sep-2012 | Happy to report that Unicode on Linux with an all-UTF8 setup works just fine for me. | |
| DocKimbel: 26-Sep-2012 | Red currently maps only to Unicode C printing functions. We could tweak the code to detect (for Unix platforms) the locale and fall back to Latin1 if required. | |
| DocKimbel: 26-Sep-2012 | Andreas: do you think we should add Latin1 locale support too or just assume that now everybody use Unicode-capable terminals? | |
| Pekr: 28-Sep-2012 | Doc, with recent discussions about Unicode, I wonder if we will have strong binary type, and myriads of to-* REBOL-like functions for various conversions between the types? | |
| DocKimbel: 7-Oct-2012 | Kaj: I noticed Unicode characters rendering does not work on my Linux ARM running on QEMU. I'm not sure yet why, I'll investigate that in the next days. | |
| DocKimbel: 13-Oct-2012 | I'm fixing the Unicode string printing issues on Linux/ARM...will post the fixes tonight. BTW, I've now an ARMHF image installed, so I'll work very soon on supporting ARMHF ABI. | |
| Kaj: 26-Oct-2012 | hello-unicode in MSDOS: | |
| DocKimbel: 27-Oct-2012 | hello-unicode in MSDOS: has he switched the DOS console to Consolas font? | |
| DocKimbel: 28-Oct-2012 | Brian: I'm aware of that. The probabilty of someone porting Red to old MSDOS (no Unicode, no multitasking, no native TCP/IP) is very close to zero. If someone does it anyway, we'll adjust our targets ID accordingly. In the meantime, I prefer typing "-t MSDOS" rather than "-t Windows-Console" on command-line. Also, it's easier to remember for everyone, after all it's just an ID, nothing else. If you are thinking about FreeDOS, which is probably a more likely target than real old MSDOS, I guess we won't have any name collision then. ;-) | |
| Kaj: 30-Oct-2012 | Is it correct that Red/System can't print Unicode on Windows like the other systems? | |
| PeterWood: 30-Oct-2012 | Probably the easiiest way would be to inculde the Red runtime and use red/unicode/load-utf8 to create a Red string and Red/Platform/print-ucs4 to print it. | |
| Pekr: 1-Nov-2012 | hello-unicode give incorrect output ... | |
| Kaj: 1-Nov-2012 | hello-Unicode is because the program source is UTF-8 instead of UTF-16 | |
| Kaj: 1-Nov-2012 | hello-Unicode is a Red/System program, so the Unicode printing is straight from the source code, without awareness | |
| DocKimbel: 10-Nov-2012 | You can add those two also, no problem. Red is already more complete than R3 on some aspects, like Unicode support. | |
| Jerry: 10-Nov-2012 | Doc, Unicode in R3 is pretty good for me. | |
| Jerry: 10-Nov-2012 | I write a book for R3 instead of R2 because R3 supports Unicode. Without Unicode, R2 is useless in China. | |
| Jerry: 10-Nov-2012 | Many years ago, I found REBOL 2 and liked it a lot, but back then REBOL didn't support Unicode, so it was useless in China/Taiwan. I wrote e-mail to Carl, but I got no feedback. So I decided to start a magazine column in China and Taiwan to introduce REBOL. My idea was to make readers love REBOL and felt the same pain (of no unicode support). I also kind of encouraged them to write e-mail to RT on the Unicode issue. | |
| Jerry: 10-Nov-2012 | After a while, Carl said (in somewhere, blog maybe) that he didn't know why REBOL had many Chinese users, and they need Unicode. So he decided to support Unicode. | |
| Jerry: 10-Nov-2012 | Doc, I am glad that Red support Unicode in the first place, so I don't have to do the same trick to you. :-) | |
| DocKimbel: 10-Nov-2012 | I remember that Unicode in R3 is mostly thanks to you. :-) No modern programming language can miss full Unicode support now, so it's a mandatory feature to have, anyway. | |
| DocKimbel: 10-Nov-2012 | In any case, you can always bypass the whole Unicode layer by reading (or converting) strings as binary! values, and then processing them the way you want (this is not recommended though, but some users might need it). | |
| BrianH: 10-Nov-2012 | For instance, users converting character encodings to Unicode, encodings like UTF8 or national encodings. | |
| BrianH: 10-Nov-2012 | Sorry if I missed the answer to this, but are you going to be doing a UTF8 binary parser for Red's source the way that R3 does for its source? Rather than a Unicode string parser, which processes the source after it's been through a codec? | |
| Endo: 10-Dec-2012 | About the case-sensitivity, What about to convert all the words into lowercase in compile time? Does it lead some unicode problems? What if a word is in Chinese, is there lower/upper cases in Chinese? | |
| BrianH: 10-Dec-2012 | Most people would prefer case-preserving behavior though, despite how difficult that is for multi-language Unicode words. | |
| DocKimbel: 26-Dec-2012 | I plan to continue working on it until 1st January to add Unicode support to the tokenizer and make the interpreter on par with the current compiler. I will then resume the work on object and ports. | |
| DocKimbel: 27-Dec-2012 | _setmode call is used to properly set the DOS console to UTF-16 (Unicode mode). | |
| Jerry: 4-Jan-2013 | It's interesting that we have all the symbols in unicode but still are lack of symbols because of we use only ASCII characters. | |
| DocKimbel: 4-Jan-2013 | Jerry: keyboards are only able to handle a tiny subset of Unicode. | |
| DocKimbel: 7-Mar-2013 | Pekr: merge is not the point, that is not what we've discussed with BrianH, Andreas and Fork. The point is just not driving users crazy when loading code in R3/Red because of obscure and arbitrary incompatibilities in the syntax. Also often the same logic rules apply to syntactic choices in both R3 and Red. The best example are the rules for defining a word! (it's not that obvious when you consider Unicode). Also the same remark applies to some basic semantics like indexing. Although the level of compatibility is at our discretion, we can diverge when we need to. I want Red to retain the best of R2, but fix some of its core design issues. Some solutions found for R3 are improvements over R2, there's no reason for Red to ignore them. Hence the common work between R3 and Red projects on some parts. | |
| DocKimbel: 7-Mar-2013 | NickA: I fully agree with you. A bare Red core has low value and not much potential to attract a large crowd. Actually building all those user-level features will be the fun part of Red project, I'm looking forward with great appetit to the moment I'll be able to work on them. Also with a solid Red core, we could provide an even better user experience than Livecode, which, e.g. still struggles to handle Unicode fully: http://www.runrev.com/products/livecode/text-and-data-processing/ We should mention that currently it�s perfectly possible to build applications that use Unicode in LiveCode, but there are some limitations. [...] We�re hard at work adding beautiful, seamless and complete Unicode support for a future version so please check back if you�re interested in that. | |
| DocKimbel: 7-Mar-2013 | http://lessons.runrev.com/spaces/lessons/buckets/809/lessons/12304-How-do-I-use-Unicode-in-Rev- In "Using character chunk expressions with unicodeText" section: set the unicodeText of field 2 to the unicodeText of field 1 Wow...doesn't look like Livecode scales up very well. In Rebol/View: set-face field1 get-face field2 | |
| BrianH: 7-Mar-2013 | The latter, the ticket needs to be rejected, I was wrong. There is another ticket about adding support for Unicode whitespace as delimiters, and we should probably try to figure out how to implement that one (though the zero-width spaces are a bit iffy). | |
| Janko: 7-Mar-2013 | aha, I misunderstood it then.. yes these unicode whitespaces are problematic.. I often have problems with them when trying processing data in bash from various documents | |
| DocKimbel: 28-Mar-2013 | Right, adding basic float support to Red is not difficult, but as floats are not needed internally to build Red, they are low priority (but if someone wants to contribute it, it will be welcome). Moreover, the runtime lexer is disposable code, it will be soon replaced by a new one with Unicode support and more complete syntax support. So extending it now for additional literal forms is a bit of waste of time. If someone is interested in implementing float support anyway, the decimal! name is reserved for a future BCD datatype, so possible names are: real! or float!. It will be a 64-bit float, so mapped underneath to Red/System float! type. A support for float32! at Red level is not planned, converting float! to float32! at Red/System level when needed (i.e. OpenGL API) should be enough. | |
| Kaj: 17-Apr-2013 | It's just that I thought Unicode was already there. Most of my future work is blocked by it | |
| DocKimbel: 17-Apr-2013 | Unicode support is there, but we don't have all the external encoders/decoders yet. | |
| DocKimbel: 17-Apr-2013 | We have hardwired the stdout/stdin Unicode support because we don't yet have the I/O infrastructure for Red (ports and devices). | |
| Kaj: 17-Apr-2013 | It's worse than having no Unicode, then you can at least get out what you put in | |
| Kaj: 17-Apr-2013 | I could, but I know very little of Unicode, so there would be a lot of overhead in getting up to speed | |
| Kaj: 17-Apr-2013 | Sticking to Latin1 is not much use these days. Many data such as web sites is in Unicode. It would be fine if it worked like R2, as a transparent passthrough, but Red eats your Unicode and won't give it back from its internal format | |
| Kaj: 26-Apr-2013 | I found out that not only does Red not support Unicode, it doesn't support Latin-1, not even on Windows | |
| Kaj: 26-Apr-2013 | The printing backend doesn't fully support Unicode, either. This works on Linux: | |
| Kaj: 26-Apr-2013 | With the only function in Red that supports Unicode: string/load | |
| Group: Ann-Reply ... Reply to Announce group [web-public] | ||
| Jerry: 6-May-2012 | R2 doesn't support Unicode, so it's useless in East Asia. | |
| Kaj: 5-Dec-2012 | To get Unicode output on Windows, you need to switch the command prompt to Consolas font | |
| DocKimbel: 8-Jan-2013 | Nice work Kaj. I'm working on Unicode support for the tokenizer, so the console should get at least Unicode support for the DevCon. I plan to write a real cross-platform console engine as nobody has stepped out to build one so far, I guess it should be ready for the DevCon. | |
| DocKimbel: 24-Mar-2013 | I will do it myself if nobody else steps in, once we get the target console implemented (Unicode LOAD, EXIT and RETURN supported,...) | |
| Group: Rebol School ... REBOL School [web-public] | ||
| Kaj: 20-Jun-2012 | One of the few advantages of R3 is processing Unicode. It fixed the Russian Syllable website | |
| Group: Databases ... group to discuss various database issues and drivers [web-public] | ||
| BrianH: 17-Mar-2012 | Like the nchar and nvarchar types. OpenDBX converts those types to ASCII, then R3 would need to convert them back to Unicode. | |
| BrianH: 17-Mar-2012 | It makes a lot more sense to have OpenDBX bindings for R2 though, since the lack of Unicode support won't matter there. | |
| Group: !REBOL3 ... General discussion about REBOL 3 [web-public] | ||
| Andreas: 21-Jan-2013 | I'd assume because only Unicode datatypes are considered any-string! now. | |
| Oldes: 23-Jan-2013 | Regarding binary not a string - string is unicode which may differ per platforms. | |
| Pekr: 31-Jan-2013 | Id depends, how fast is CALL, but especially on Linux, there should be very little overhead. E.g. I found out, that PHP, for Unicode conversions, just calls iconv. If you don't call the function in loop, I would go the CALL way, with tiny wrapper parsing results back. But - CALL on R3 misses /output and /wait ... | |
| Rebolek: 16-Feb-2013 | There's a bug in SAVE/HEADER when using Unicode characters in header. See http://issue.cc/r3/1953 | |
| Andreas: 26-Feb-2013 | No bug, READ does no longer automatically decode binary to strings. Use READ/string to obtain a a Unicode string obtained by decoding the binary with UTF-8. | |
| BrianH: 7-Mar-2013 | The main problem with Unicode whitespace delimiters is that R3's syntax parser isn't actually a Unicode parser at all, it's a byte-oriented parser. | |
| BrianH: 7-Mar-2013 | This means that the difference between an ASCII character and a higher Unicode codepoint is significant. ASCII characters can be detected with a single byte of lookahead. Higher codepoints require multiple bytes of lookahead. That means that for most parsing models any rules that require multi-byte stop sequences are quite a bit more complicated, slower, and for some parsing models impossible. So I'm hoping we can fix this. | |
| GiuseppeC: 9-Apr-2013 | Excuses have reasons. Lets dress the clothing of someone which should adopt something new rather and unknown instead of something old and well known. That programmer should adopt an ALPHA labeled product that let flash in his mind difficulties like "BUGS, NO DOCUMENTATION, SUDDEN CHANGES" Apart from Unicode, we have no comparison over REBOL2 for new and better feature which could motivate the programmer. Ladislav, consideer that people are humans. They have obstacles in their life. It is our role to understand which obstacles they have and how to "reframe the context" to avoid them. | |
| Ladislav: 9-Apr-2013 | Apart from Unicode, we have no comparison over REBOL2 for new and better feature which could motivate the programmer. - wrong again, you surely heard about: - essentially all cycles being natives in R3 - money implemented as a "truly decimal" format - functions implemented differently to be compatible with multithreading, etc. - closures implemented natively - Parse improved significantly - R3GUI improved - new modules feature - I do not even have the time to list all... | |
{kind=link}
{kind=link}
{kind=link}
| 1 / 596 | [1] | 2 | 3 | 4 | 5 | 6 |